5.1 KiB

Kokoro TTS API
FastAPI wrapper for Kokoro-82M text-to-speech model, providing an OpenAI-compatible endpoint with:
- NVIDIA GPU accelerated inference (or CPU) option
- automatic chunking/stitching for long texts
- very fast generation time (~35-49x RTF)
Quick Start
-
Install prerequisites:
- Install Docker Desktop
- Install Git (or download and extract zip)
-
Clone and start the service:
# Clone repository
git clone https://github.com/remsky/Kokoro-FastAPI.git
cd Kokoro-FastAPI
# For GPU acceleration (requires NVIDIA GPU):
docker compose up --build
# For CPU-only deployment (~10x slower, but doesn't require an NVIDIA GPU):
docker compose -f docker-compose.cpu.yml up --build
Quick tests (run from another terminal):
Test OpenAI compatibility:
# Test OpenAI Compatibility
python examples/test_openai_tts.py
# Test all available voices
python examples/test_all_voices.py
OpenAI-Compatible API
# Using OpenAI's Python library
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8880", api_key="not-needed")
response = client.audio.speech.create(
model="kokoro", # Not used but required for compatibility, also accepts library defaults
voice="af_bella",
input="Hello world!",
response_format="mp3"
)
response.stream_to_file("output.mp3")
Or Via Requests:
import requests
response = requests.get("http://localhost:8880/v1/audio/voices")
voices = response.json()["voices"]
# Generate audio
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"model": "kokoro", # Not used but required for compatibility
"input": "Hello world!",
"voice": "af_bella",
"response_format": "mp3", # Supported: mp3, wav, opus, flac
"speed": 1.0
}
)
# Save audio
with open("output.mp3", "wb") as f:
f.write(response.content)
Voice Combination
Combine voices and generate audio:
import requests
# Create combined voice (saved locally on server)
response = requests.post(
"http://localhost:8880/v1/audio/voices/combine",
json=["af_bella", "af_sarah"]
)
combined_voice = response.json()["voice"]
# Generate audio with combined voice
response = requests.post(
"http://localhost:8880/v1/audio/speech",
json={
"input": "Hello world!",
"voice": combined_voice,
"response_format": "mp3"
}
)
Performance Benchmarks
Benchmarking was performed on generation via the local API using text lengths up to feature-length books (~1.5 hours output), measuring processing time and realtime factor. Tests were run on:
- Windows 11 Home w/ WSL2
- NVIDIA 4060Ti 16gb GPU @ CUDA 12.1
- 11th Gen i7-11700 @ 2.5GHz
- 64gb RAM
- WAV native output
- H.G. Wells - The Time Machine (full text)
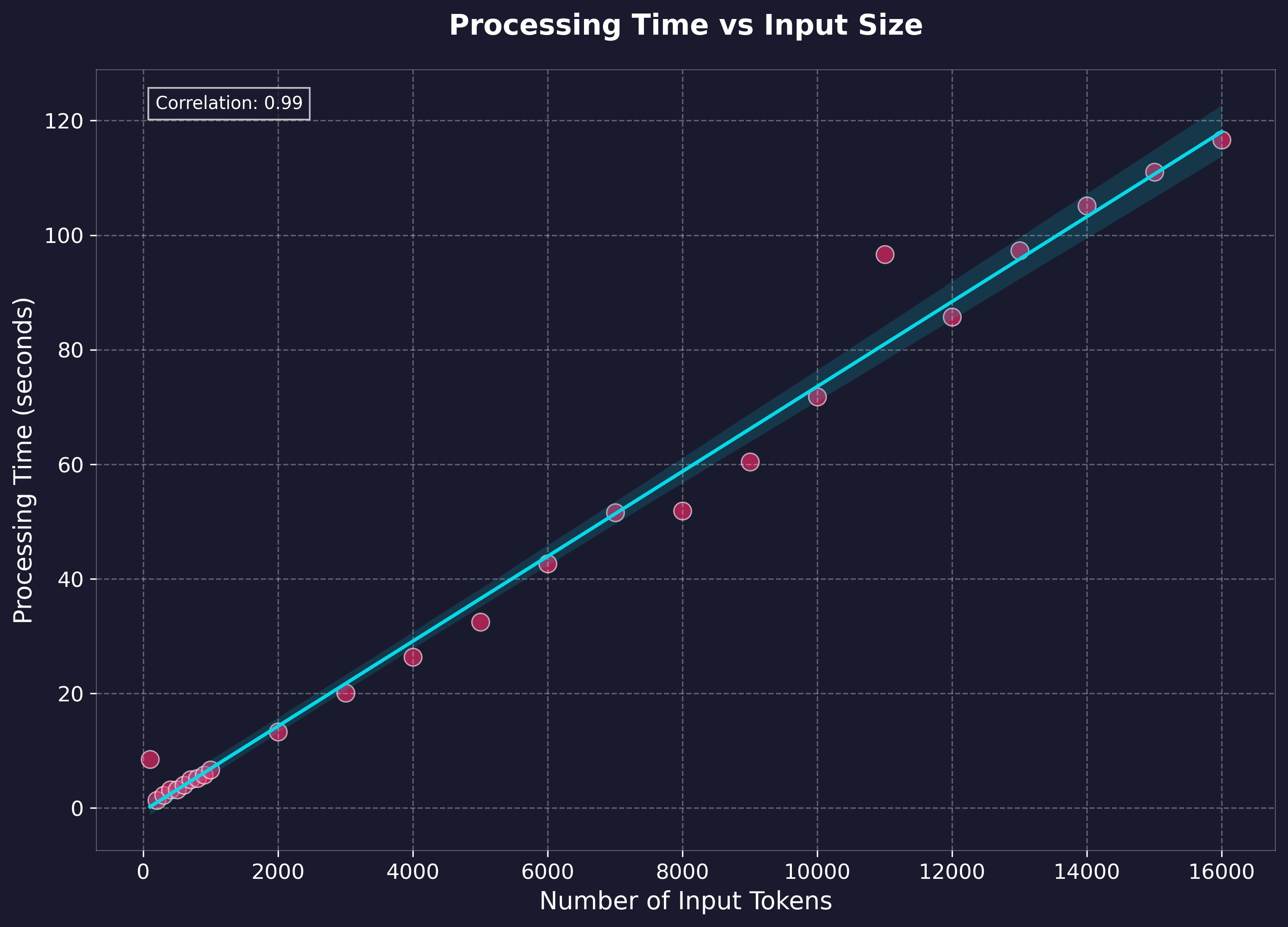
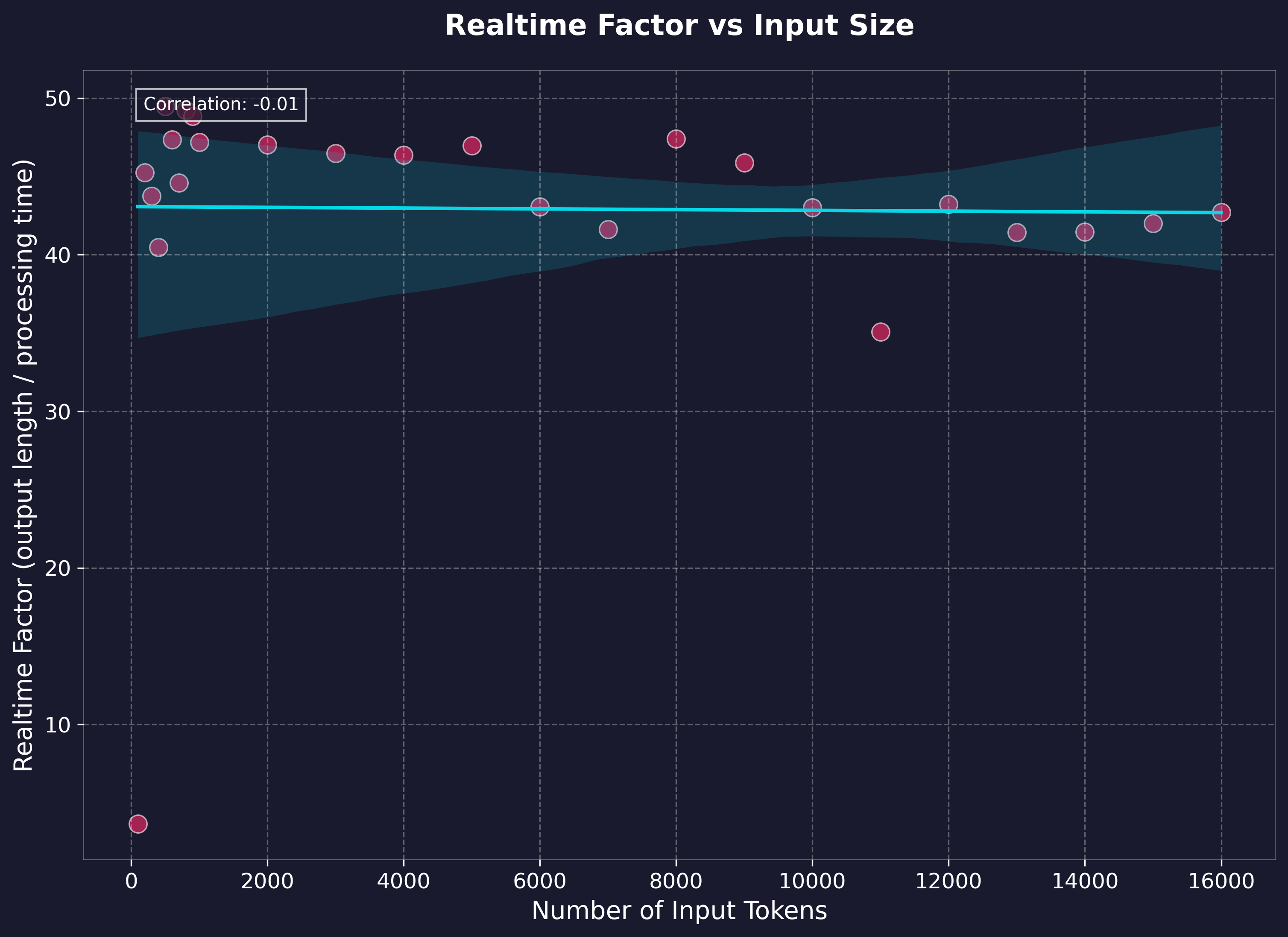
Key Performance Metrics:
- Realtime Factor: Ranges between 35-49x (generation time to output audio length)
- Average Processing Rate: 137.67 tokens/second (cl100k_base)
Features
- OpenAI-compatible API endpoints
- GPU-accelerated inference (if desired)
- Multiple audio formats: mp3, wav, opus, flac, (aac & pcm not implemented)
- Natural Boundary Detection:
- Automatically splits and stitches at sentence boundaries to reduce artifacts and maintain performacne
- Voice Combination:
- Averages model weights of any existing voicepacks
- Saves generated voicepacks for future use

Note: CPU Inference is currently a very basic implementation, and not heavily tested
Model
This API uses the Kokoro-82M model from HuggingFace.
Visit the model page for more details about training, architecture, and capabilities. I have no affiliation with any of their work, and produced this wrapper for ease of use and personal projects.
License
This project is licensed under the Apache License 2.0 - see below for details:
- The Kokoro model weights are licensed under Apache 2.0 (see model page)
- The FastAPI wrapper code in this repository is licensed under Apache 2.0 to match
- The inference code adapted from StyleTTS2 is MIT licensed
The full Apache 2.0 license text can be found at: https://www.apache.org/licenses/LICENSE-2.0